
Groo
정렬에 대해서 본문

안녕하세요, 오늘은 정렬 알고리즘에 대해서 여러분들에게 소개하려고합니다.
정렬 알고리즘의 종류는 정말 다양하고 내용도 많습니다. 천천히 정렬 알고리즘에 대해서 살펴보도록 하겠습니다.
📊 정렬의 개념이란?
정렬은 간단한 의미로 이름, 성별, 키와 같이 특정 항목의 대소 관계에 따라 데이터 집합을 일정한 순서로 나열하는 것입니다. 예를 들어 수학에서는 이 정렬의 개념을 활용하여 오름차순, 내림차순이라는 개념이 존재하며 실생활에서도 정렬을 많이 활용하고 있습니다.

🔈 정렬 알고리즘의 핵심 요소는?
정렬 알고리즘의 핵심 요소는 아래와 같이 간단합니다. 대부분의 정렬 알고리즘은 교환, 선택, 삽입을 통해서 거의 모든 기능을 구현할 수 있으며 만약 이를 잘 활용하지 못한다면 정렬 알고리즘을 구현하는 것은 역시 어려울 것이라고 저는 생각하고 있습니다.
정렬 알고리즘의 핵심 요소
1. 교환, 선택, 삽입이며 대부분의 정렬 알고리즘은 이 세 가지 요소를 응용한 것이다.
🛁 버블 정렬은 무엇인가?
버블 정렬은 이웃한 두 요소의 대소 관계를 서로 비교하여 교환과 반복을합니다. 대체적으로 오름차순으로 각 요소들을 구성합니다. 아래의 간단한 예시를 통해 버블 정렬에 대해서 더 자세히 알아보도록 하겠습니다. 아래의 배열은 요솟수가 7인 간단한 배열입니다.

위는 버블 정렬이 진행되는 순서를 나타냈습니다. 버블 정렬은 배열의 맨 끝에서 부터 비교를 진행합니다. 배열의 맨 끝의 요소와 그 앞의 요소 값을 비교하여 만약 앞의 요소의 값이 뒤의 요소의 값보다 더 크다면 교환을 진행하고 그렇지 않다면 교환을 하지 않습니다.
이 과정을 n-1 회 진행한다면 배열에서 가장 작은 요소가 배열의 맨 처음으로 이동하게됩니다. 그리고 이러한 비교, 교환 작업을 패스라고 부릅니다. 위 구조는 첫 번째 패스의 과정을 나타낸 것입니다. 그 후 두 번째 패스의 과정 또한 똑같은 방식으로 진행됩니다.

두 번째 패스 과정 또한 이전 패스의 과정과 거의 비슷합니다. 그러나 비교, 교환의 횟수가 1회 적습니다. 그 이유는 패스의 과정을 한 번 수행할 때마다 정렬할 요소가 하나씩 줄어들기 때문입니다. 따라서 패스를 K회 수행한다면 앞쪽의 요소가 K개 정렬된 것입니다.
이번에는 버블 정렬의 개념을 활용하여 이를 코드로 작성해보겠습니다. 코드를 작성할 때 중요한 내용이 존재합니다. 먼저 전체 패스의 횟수는 배열 요솟수의 크기에 따라 n-1 회 진행되어야합니다. 또한 한 번의 패스 과정 안에서 진행되는 각 요소 값의 비교, 교환을 위해 첫 번째 시작 값은 n-1의 값으로 배열의 맨 끝 값으로 지정해야합니다. 또한 종료조건은 현재 패스의 값보단 클 때까지 입니다.
public class BubbleSort {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("버블 정렬(버전 1)");
System.out.print("요솟수 : "); int input = scanner.nextInt();
int[] x = new int[input];
for(int i = 0; i < input; i++){
System.out.print("x[" + i +"] : ");
x[i] = scanner.nextInt();
}
bubbleSort(x, input);
System.out.println("오름차순으로 정렬했습니다.");
for(int i = 0; i < input; i++){
System.out.println("x[" + i + "] = " + x[i]);
}
}
public static void bubbleSort(int[] x, int input){
for(int i = 0; i < input - 1; i++){
for(int j = input - 1; j > i; j--){
if(x[j - 1] > x[j]) swap(x, j - 1, j);
}
}
}
public static void swap(int[] x, int idx1, int idx2){
int temp = x[idx1];
x[idx1] = x[idx2];
x[idx2] = temp;
}
}
코드를 작성할 때 중요하다고 말하였던 내용은 위 코드에서 bubleSort 메서드 안에 존재하는 코드입니다. 2중 for문으로 구성이 되었으며 바깥의 변수 i는 패스의 횟수를 기록하며 내부의 변수 j는 패스 과정 속에서 배열의 각 요소들을 비교 교환하는 역할을합니다.
😛 단순 선택 정렬은 무엇인가?
단순 선택 정렬은 배열에서 가장 작은 요소의 값을 선택해 배열의 앞 부분으로 각각 이동을 시키는 정렬 알고리즘입니다. 수 많은 정렬 알고리즘들 중에서 구현하기가 제일 간단하다고 저는 생각합니다. 아래의 구조를 보면 어렵지 않고 쉽게 이해를 할 수 있을 것입니다.
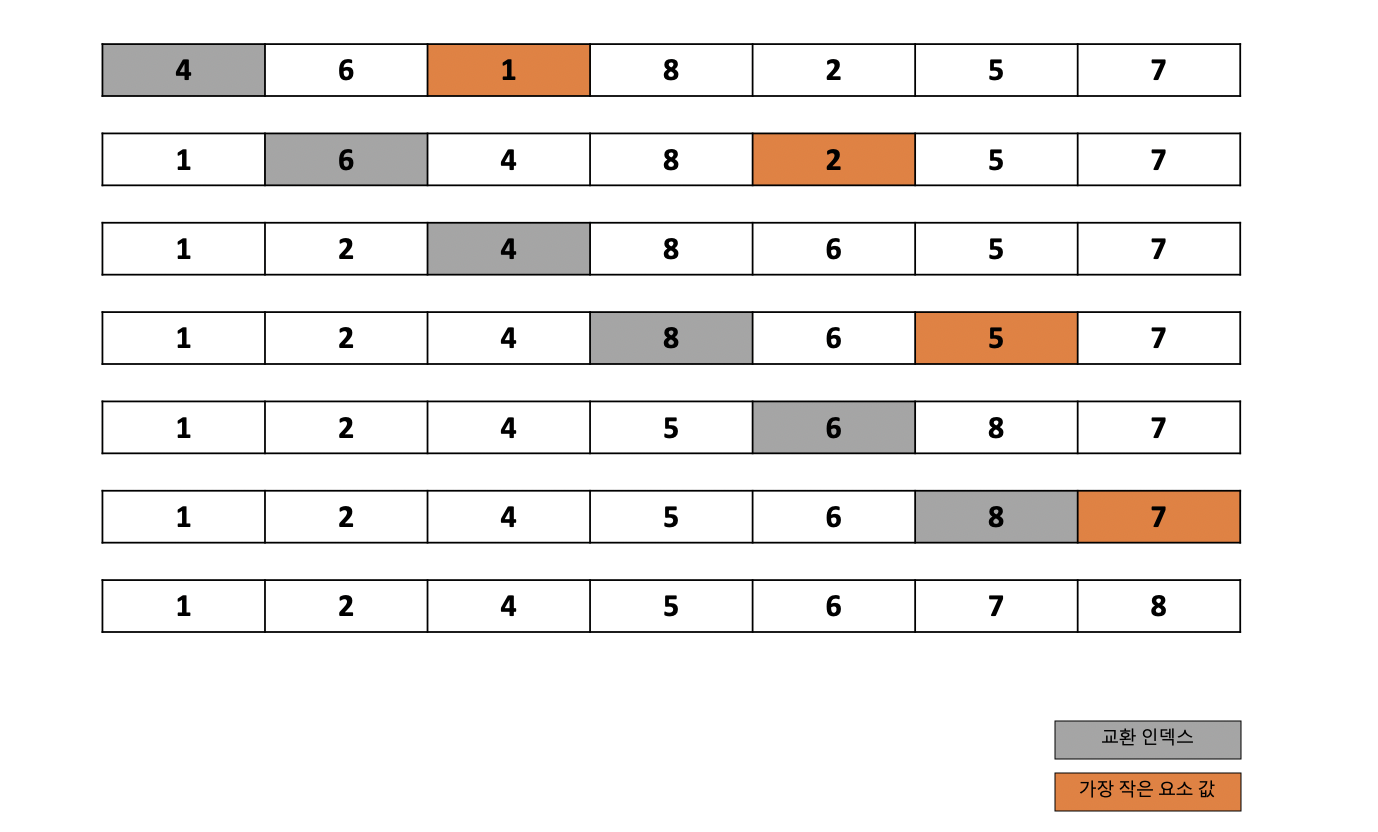
위의 사진은 요솟수가 7인 배열에서 단순 선택 정렬 알고리즘을 구현한 것입니다. 회색 배경의 의미는 교환할 인덱스의 자리를 나타내며 이 값을 최소값으로 설정합니다. 그 후 회색과 이전의 값을 제외한 요소들 중 가장 작은 값의 요소를 주황색으로 설정합니다.
위 사진의 상황처럼 만약 이 주황색의 값이 회색의 값보다 더 작다면 이 둘을 변경시켜주고 만약 그렇지 않고 주황색의 값이 회색의 값보다 더 크다면 이 둘을 서로 변경시켜주지않습니다. 그럼 이제 단순 선택 정렬의 교환 과정과 코드를 보도록하겠습니다.
단순 선택 정렬의 교환 과정
1. 아직 정렬하지 않은 요소에서 가장 작은 키의 값을 선택합니다.
2. 가장 작은 키의 값이 만약 각 교환 인덱스의 값 보다 작다면 서로 교환합니다.
public class SelectionSort {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("단순 선택 정렬");
System.out.print("요솟수 : "); int input = scanner.nextInt();
int[] x = new int[input];
for(int i = 0; i < input; i++){
System.out.print("x[" + i +"] : ");
x[i] = scanner.nextInt();
}
selectionSort(x, input);
System.out.println("단순 선택 정렬을 진행하였습니다.");
for(int i = 0; i < input; i++){
System.out.println("x[" + i + "] = " + x[i]);
}
}
public static void selectionSort(int[] x, int n){
for(int i = 0; i < n - 1; i++){
int min = i;
for(int j = i + 1; j < n; j++){
if(x[j] < x[min]) min = j;
}
swap(x, i, min);
}
}
public static void swap(int[] x, int idx1, int idx2){
int temp = x[idx1];
x[idx1] = x[idx2];
x[idx2] = temp;
}
}이전의 버블 정렬을 구현한 코드에서 bubbleSort 메서드가 selectionSort 메서드로 변경된 것의 차이점 밖에 존재하지 않습니다. 이 메서드에서는 min 지역 변수 값을 교환 인덱스로 설정을 해두고 2중 for문에서 min보다 작은 값을 찾고 있는 것을볼 수있습니다.
😎 단순 삽입 정렬을 무엇인가?
단순 삽입 정렬은 선택한 요소를 그보다 더 앞쪽의 알맞은 위치로 삽입하는 작업을 반복하는 정렬입니다. 단순 선택 정렬과 비슷하지만 단순 삽입 정렬 알고리즘이 조금 더 안전하며 구조적으로 차이점이 존재합니다. 알고리즘의 구조를 살펴보도록하겠습니다.
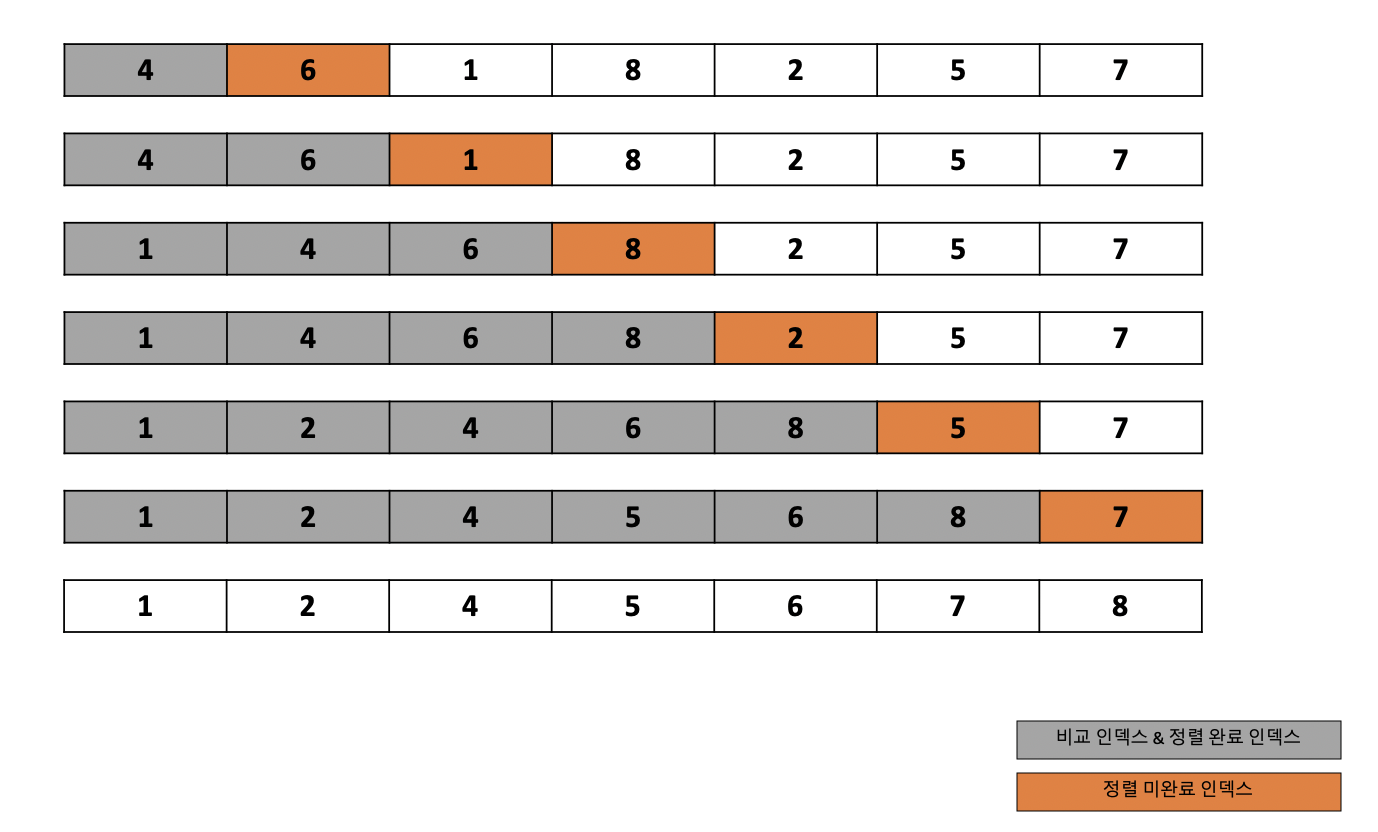
위 사진의 구조처럼 단순 삽입 정렬은 주황색으로 선택된 값이 정렬이 미완료된 인덱스의 값이며 왼쪽 회색의 값은 이미 정렬이 되었으며 주황색값과 비교를 진행합니다. 주황색의 인덱스 값은 왼쪽의 회색 값과 비교를하면서 자신이 들어가야하는 자리를 찾습니다.
단순 삽입 정렬의 반복 종료 조건
1. 정렬된 열의 왼쪽 끝에 도달한다.
2. 선택한 요소보다 값이 작거나 같은 배열의 인덱스 값을 발견한다.
public class InsertionSort {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("단순 삽입 정렬");
System.out.print("요솟수 : "); int input = scanner.nextInt();
int[] x = new int[input];
for(int i = 0; i < input; i++){
System.out.print("x[" + i +"] : ");
x[i] = scanner.nextInt();
}
insertionSort(x, input);
System.out.println("단순 삽입 정렬을 진행하였습니다.");
for(int i = 0; i < input; i++){
System.out.println("x[" + i + "] = " + x[i]);
}
}
public static void insertionSort(int x[], int input){
for(int i = 1; i < input; i++){
int j;
int tmp = x[i];
for(j = i; j > 0 && x[j - 1] > tmp; j--){
x[j] = x[j - 1];
}
x[j] = tmp;
}
}
}위의 코드에서 insertSort 메서드를 보겠습니다. i 변수는 아직 정렬되지 않은 주황색을 의미하고 j 변수는 이미 정렬된 회색을 의미합니다. 2중 for 반복문에 투입되기 전 tmp 변수에 주황색 선택한 값을 저장해둡니다. 그 후 아래의 2중 for 반복문에 투입됩니다.
만약 반복 조건에 성립을 한다면 왼쪽 요소 회색 인덱스의 값을 한 칸씩 오른쪽으로 이동시킵니다. 이 과정을 반복문의 종료 조건이 성립할 때까지 계속 진행하며 만약 종료 조건에 성립하지 않는다면 반복문을 탈출해 현재 j 값의 인덱스에 tmp 변수 값을 대입합니다.
🚀 퀵 정렬은 무엇인가?
퀵 정렬은 배열에서 어떠한 기준점을 지정하여 그 기준으로부터 왼쪽, 오른쪽으로 그룹을 계속 나누어가는 정렬입니다. 이 알고리즘은 정렬 알고리즘들 중에서 아주 빠른 알고리즘에 속하며 그 과정 또한 이전의 알고리즘들보다 복잡하다고 말할 수 있습니다.
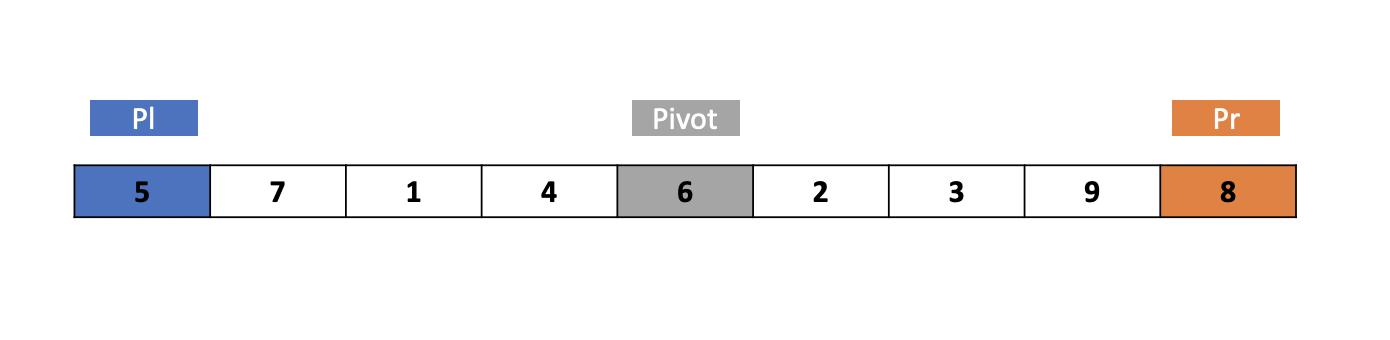
퀵 정렬 알고리즘을 구현하기 위해서는 몇 가지의 단어를 알아야합니다. 배열에서 한 기준점을 나타내는 피벗, 배열의 왼쪽 끝 요소 인덱스를 가리키는 Pl, 오른쪽 끝 요소 인덱스를 가리키는 Pr을 활용하여 퀵 정렬을 구현가능합니다. 먼저 본연의 퀵 정렬을 구현해보기 전에 피벗을 기준으로 Pl, Pr이 어떤 과정으로 움직이며 값들이 교환되고 그룹이 나누어지는지에 대해서 알아보도록 하겠습니다.
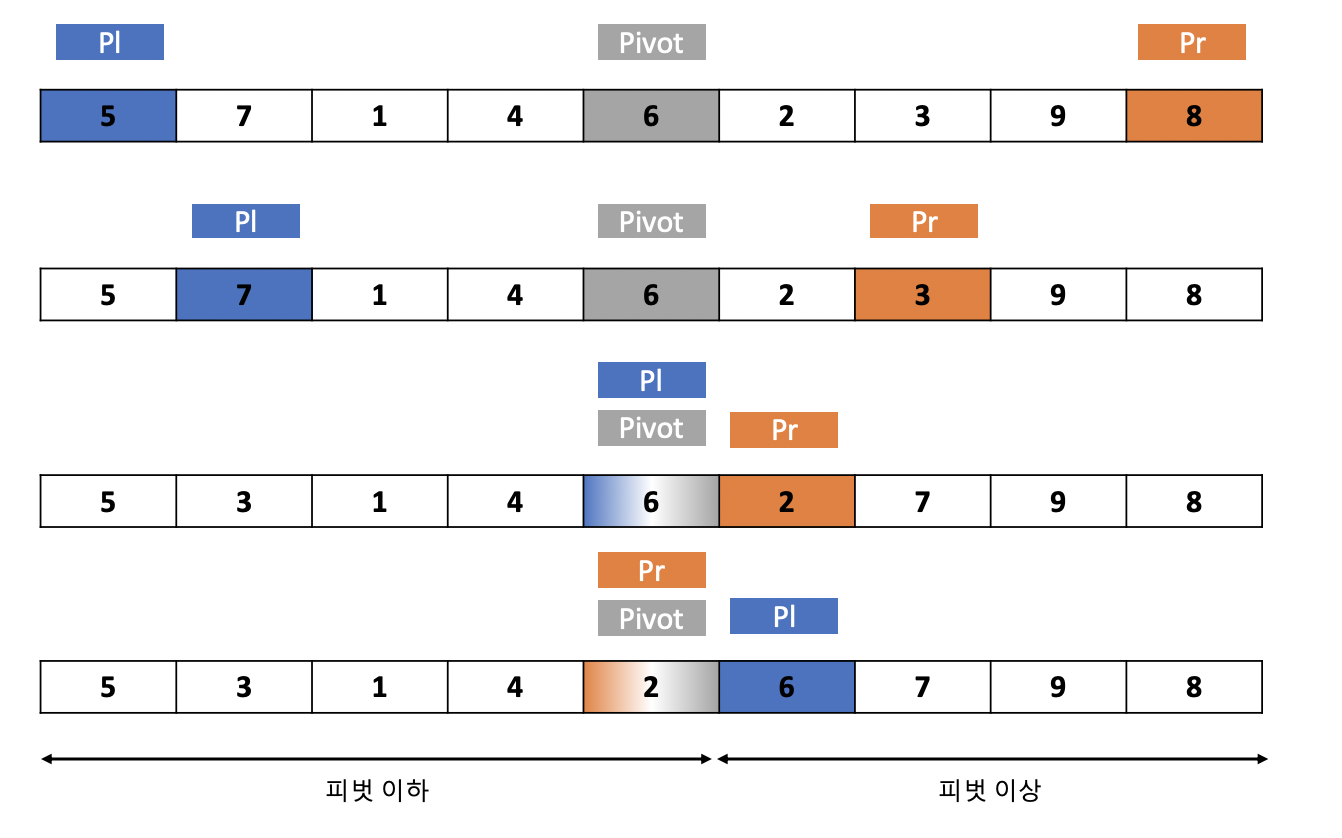
위의 사진은 배열에서 피벗과 Pl, Pr이 움직이며 값들을 교환하고 그룹을 나누는 과정입니다. Pl은 피벗보다 값이 크거나 같은 값을 만날 때까지 오른쪽으로 움직이며 스캔하며 반면에 Pr은 피벗보다 작거나 같은 값을 만날 때까지 왼쪽으로 스캔하며 움직입니다.
위의 두 번째 상황을 보면 Pr은 Pl보다 더 높은 인덱스를 가지고 있으며 Pl이 위치한 지점은 피벗 값이상의 요소가 있는 지점이며 Pr이 위치한 지점은 피벗 값 이하의 요소가 있는 지점입니다. 여기서 Pl과 Pr이 가리키는 인덱스 요소 값을 교환합니다. 같은 방식으로 반복이 진행되며 만약 Pl이 Pr보다 더 높은 인덱스를 가지게 된다면 반복을 종료하고 피벗 이하와 피벗 이상의 그룹으로 나뉩니다.
Pl과 Pr이 움직이는 조건
1. x[Pl] >= Pivot이 성립하는 요소를 찾을 때까지 오른쪽으로 움직이며 스캔합니다.
2. x[Pr] <= Pivot이 성립하는 요소를 찾을 때까지 왼쪽으로 움직이며 스캔합니다.
Pl과 Pr의 교환, 종료 조건
1. Pr이 Pl보다 더 높은 인덱스를 가지고 있다면 각 인덱스 요소의 값을 교환합니다.
2. Pl이 Pr보다 더 높은 인덱스를 가지고 있다면 피벗 이하와 피벗 이상으로 그룹을 나눕니다.
public class Partition {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("배열을 나눕니다.");
System.out.print("요솟수 : "); int input = scanner.nextInt();
int[] x = new int[input];
for(int i = 0; i < input; i++){
System.out.print("x[" + i +"] : ");
x[i] = scanner.nextInt();
}
partition(x, input);
}
public static void partition(int x[], int input){
int pl = 0;
int pr = input - 1;
int pivot = x[input / 2];
do{
while(x[pl] < pivot) pl++;
while(x[pr] > pivot) pr--;
if(pl <= pr) swap(x, pl++, pr--);
}while(pl <= pr);
System.out.println("피벗의 값은 " + pivot + "입니다.");
System.out.println("피벗 이하의 그룹");
for(int i = 0; i <= pl - 1; i++){
System.out.println(x[i] + " ");
}System.out.println();
if(pl > pr + 1){
System.out.println("피벗과 일치하는 그룹");
for(int i = pr + 1; i <= pl - 1; i++){
System.out.println(x[i] + " ");
}System.out.println();
}
System.out.println("피벗 이상의 그룹");
for(int i = pr + 1; i < input; i++){
System.out.println(x[i] + " ");
}System.out.println();
}
public static void swap(int[] x, int idx1, int idx2){
int temp = x[idx1];
x[idx1] = x[idx2];
x[idx2] = temp;
}
}partition 메서드에서 pl, pr, pivot 변수의 값들을 초기화해줍니다. 그 후 do ~ while문 안에서 pr의 값이 pl보다 클 때까지 계속 pl과 pr을 움직이며 값들을 교환시켜주고 있습니다. 그 후 do ~ while문을 탈출하고 피벗 이하, 이상 두 가지 그룹으로 나눕니다.
그럼 이제 퀵 정렬의 Pl, Pr의 값이 어떤 방식으로 이동되고 교환이되어 그룹이 나누어지는지에 대해서 알았다면 진정한 퀵정렬에 대해서 알아보겠습니다. 앞에서 배웠던 개념을 활용하고 코드를 활용한다면 달라지는게 거의 없기 때문에 어렵지 않을 것입니다.
앞에서는 피벗 이하, 이상의 그룹 2가지로만 나누었습니다. 그러나 이번에는 이 과정을 요소의 개수가 1개인 그룹이 나올 때까지 계속 반복하여 그룹을 나눕니다. 요소의 개수가 1개인 그룹을 찾는 방법은 아래에 나와있으며 이전에 배운 재귀 방식을 함께 사용합니다.
그룹 분할 조건
1. pr이 x[0]보다 오른쪽에 있다면(left < pr) 왼쪽 그룹을 나눕니다.
2. pl이 x[8]보다 왼쪽에 있다면(pl < right) 오른쪽 그룹을 나눕니다.
public class QuickSort {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("퀵 정렬");
System.out.print("요솟수 : "); int input = scanner.nextInt();
int[] x = new int[input];
for(int i = 0; i < input; i++){
System.out.print("x[" + i +"] : ");
x[i] = scanner.nextInt();
}
quickSort(x, 0, input - 1);
System.out.println("오름차순으로 정렬했습니다.");
for(int i = 0; i < input; i++){
System.out.println("x[" + i + "] = " + x[i]);
}
}
public static void quickSort(int x[], int left, int right){
int pl = left;
int pr = right;
int pivot = x[(pl + pr) / 2];
do{
while(x[pl] < pivot) pl++;
while(x[pr] > pivot) pr--;
if(pl <= pr) swap(x, pl++, pr--);
}while(pl <= pr);
if(left < pr) quickSort(x, left, pr);
if(pl < right) quickSort(x, pl, right);
}
public static void swap(int[] x, int idx1, int idx2) {
int temp = x[idx1];
x[idx1] = x[idx2];
x[idx2] = temp;
}
}위의 quickSort 메서드를 보면 이전의 partition 메서드에서 구성하였던 내용들이 그대로 존재합니다. 추가된 점은 if문 2개가 포함되어있습니다. 이것은 위의 그룹 분할 조건을 코드로 구현한 것이며 재귀의 방식을 활용하여 그룹을 계속 나누는 작업을 수행합니다.
🤩 병합 정렬은 무엇인가?
병합 정렬은 배열을 앞 부분과 뒷부분으로 나누어 각각 정렬한 다음 다시 병합하는 작업을 반복하여 수행하는 정렬 알고리즘이라고 할 수 있습니다. 앞에서 배운 퀵 정렬과 조금 비슷하다고 말할 수도 있지만 다른 부분이 존재하니 한 번 알아보도록 하겠습니다.
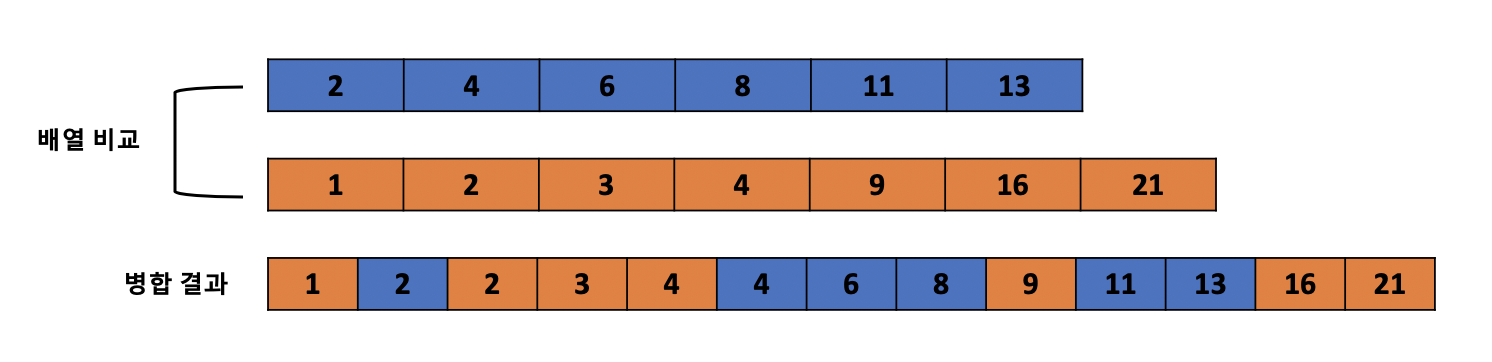
위의 구조를 보면 세 개의 배열이 존재합니다. 첫 번째 남색 배열을 A, 두 번째 주황색 배열을 B, 세 번째 통합된 배열을 C라고 부르겠습니다. 먼저 전체적인 흐름은 배열 A와 B를 서로 비교하여 배열 C에 병합시키는 것입니다. 조금 더 구체적으로 설명한다면 배열 A, B에서 각 값을 비교할 때는 첫 번째 인덱스의 값들부터 비교하며 둘 중 더 작은 값을 C배열에 추가시킵니다. 이 과정을 반복합니다.
진정한 병합 정렬을 구현해보기 전 위의 구조를 코드로 한 번 나타내보도록하겠습니다. 이 작업은 추후 병합 정렬을 실제로 구현할 때도 정말로 중요하다고 말할 수 있습니다. 아래의 코드에서는 위의 구조에서 사용한 배열을 그대로 사용하도록 하겠습니다.
public class MergeArray {
public static void main(String[] args) {
int[] a = {2, 4, 6, 8, 11, 13};
int[] b = {1, 2, 3, 4, 9, 16, 21};
int[] c = new int[13];
System.out.println("두 배열의 병합");
merge(a, a.length, b, b.length, c);
System.out.println("배열 a와 b를 병합하여 배열 c에 저장했습니다.");
System.out.println("배열 a");
for(int i = 0; i < a.length; i++){
System.out.println("a[" + i + "] = " + a[i]);
}
System.out.println("배열 b");
for(int i = 0; i < b.length; i++){
System.out.println("b[" + i + "] = " + b[i]);
}
System.out.println("배열 c");
for(int i = 0; i < c.length; i++){
System.out.println("c[" + i + "] = " + c[i]);
}
}
public static void merge(int[] a, int na, int[] b, int nb, int[] c){
int pa = 0, pb = 0, pc = 0;
while(pa < na && pb < nb){
c[pc++] = (a[pa] <= b[pb]) ? a[pa++] : b[pb++];
}
while(pa < na){
c[pc++] = a[pa++];
}
while(pb < nb){
c[pc++] = b[pb++];
}
}
}merge 메서드에서는 pa, pb, pc라는 변수를 0으로 초기화하고 있습니다. 이것들은 배열 A, B, C를 스캔할 때 각 배열의 인덱스를 가리키는 역할을 합니다. 첫 번째 While문은 배열 A와 B의 각 인덱스 값을 서로 비교하여 C배열에 저장하는 작업을 하고 있습니다.
두 번째 While문은 배열 B의 모든 요소를 배열 C로 복사하고 배열 A에는 아직 복사하지 못한 요소가 남아 있을 가능성이 있기 때문에 배열 A에 남아있는 각 인덱스의 값을 배열 C로 이동시킵니다. 마지막 While문 또한 위의 내용과 같은 구조입니다.
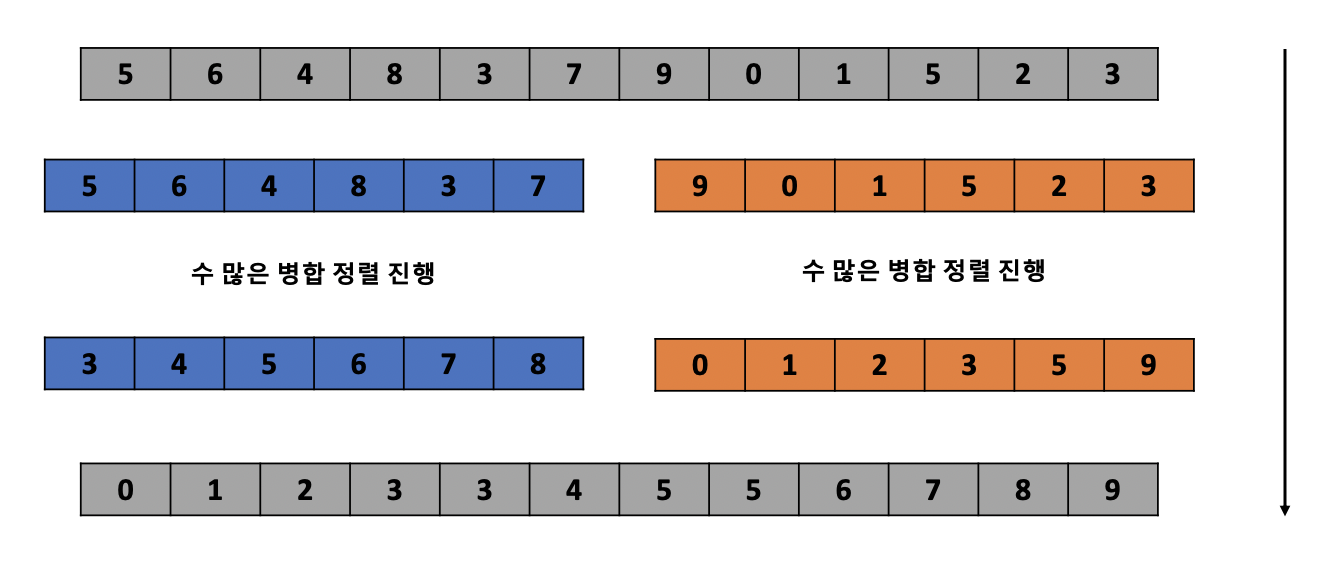
그럼 이제 위 구조와 같이 병합 정렬을 제대로 구현해보도록 하겠습니다. 병합 정렬을 구현하는 것은 위 코드의 내용을 대부분 활용하며 이번 또한 퀵 정렬을 구현할 때와 마찬가지로 재귀의 방식을 활용합니다. 따라서 재귀를 정확히 이해하는 것이 중요합니다.
병합 정렬 알고리즘의 순서도
1. 배열의 앞부분을 병합 정렬로 정렬을 반복합니다. (배열의 요소 개수가 2개 이상인 경우)
2. 배열의 뒷부분을 병합 정렬로 정렬을 반복합니다. (배열의 요소 개수가 2개 이상인 경우)
3. 배열의 앞부분과 뒷부분을 병합합니다.
public class MergeSort {
public static int[] buff;
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("병합 정렬");
System.out.print("요솟수 : "); int input = scanner.nextInt();
int[] x = new int[input];
for(int i = 0; i < input; i++){
System.out.print("x[" + i + "] : ");
x[i] = scanner.nextInt();
}
mergeSort(x, input);
System.out.println("오름차순으로 정렬했습니다.");
for(int i = 0; i < input; i++){
System.out.println("x[" + i + "] = " + x[i]);
}
}
public static void mergeSort(int[] x, int input){
buff = new int[input];
__mergeSort(x, 0, input -1);
buff = null;
}
public static void __mergeSort(int[] x, int left, int right){
if(left < right){
int i;
int center = (left + right) / 2;
int p = 0, j = 0, k = left;
__mergeSort(x, left, center);
__mergeSort(x, center + 1, right);
for(i = left; i <= center; i++){
buff[p++] = x[i];
}
while(i <= right && j < p){
x[k++] = (buff[j] < x[i]) ? buff[j++] : x[i++];
}
while(j < p){
x[k++] = buff[j++];
}
}
}
}전역 변수 buff는 각 배열의 값을 잠시 비교하기 위해 사용하는 작업용 배열입니다. __mergeSort 매서드를 보면 매개변수로 배열과 left, right 값을 전달 받고 있습니다. 이 값들은 프로그램을 구현하는데 있어서 중요한 역할을 합니다. left의 값이 right의 값보다 작다는 것은 배열의 요소 개수가 2개 이상이되지 못한다는 의미이기 때문에 더 이상의 병합 정렬을 수행하지 못하도록 합니다.
그 후 왼쪽, 오른쪽 순서로 재귀를 호출합니다. 그 아래의 For문에서는 x배열에 있는 값들을 잠시 buff 배열에 추가를 한 후 While문에서 값의 크기를 비교해 다시 x배열에 정상적인 값을 추가해줍니다. 그 아래의 While문에서는 buff 배열의 나머지 요소를 배열 X에 추가해주는 것을 볼 수 있습니다. 구조적인 부분은 앞에서 설명을 하였기 때문에 코드를 통해서만으로 이해가 가능할 것입니다.
이해를 위한 살짝의 팁을 주자면 buff 배열은 임시의 배열이라고 생각을 하면 좋을 것같습니다. 이 배열에 임시로 값을 저장해두고 실제 배열 X와 각각의 인덱스 값을 서로 비교하여 더 작은 값을 순서대로 다시 X배열에 추가하는 것이라고 생각하시면 될 것같습니다.
🧑🏫 힙 정렬은 무엇인가?
힙 정렬은 힙을 사용하여 정렬하는 알고리즘입니다. 힙이란 부모와 자식 요소의 관계가 일정한 상태를 의미합니다. 예를 들어 부모의 값이 자식의 값보다 항상 크거나 또는 작다면 힙의 조건이 성립한다는 것을 알 수 있습니다. 이들은 완전이진트리로 나타냅니다.
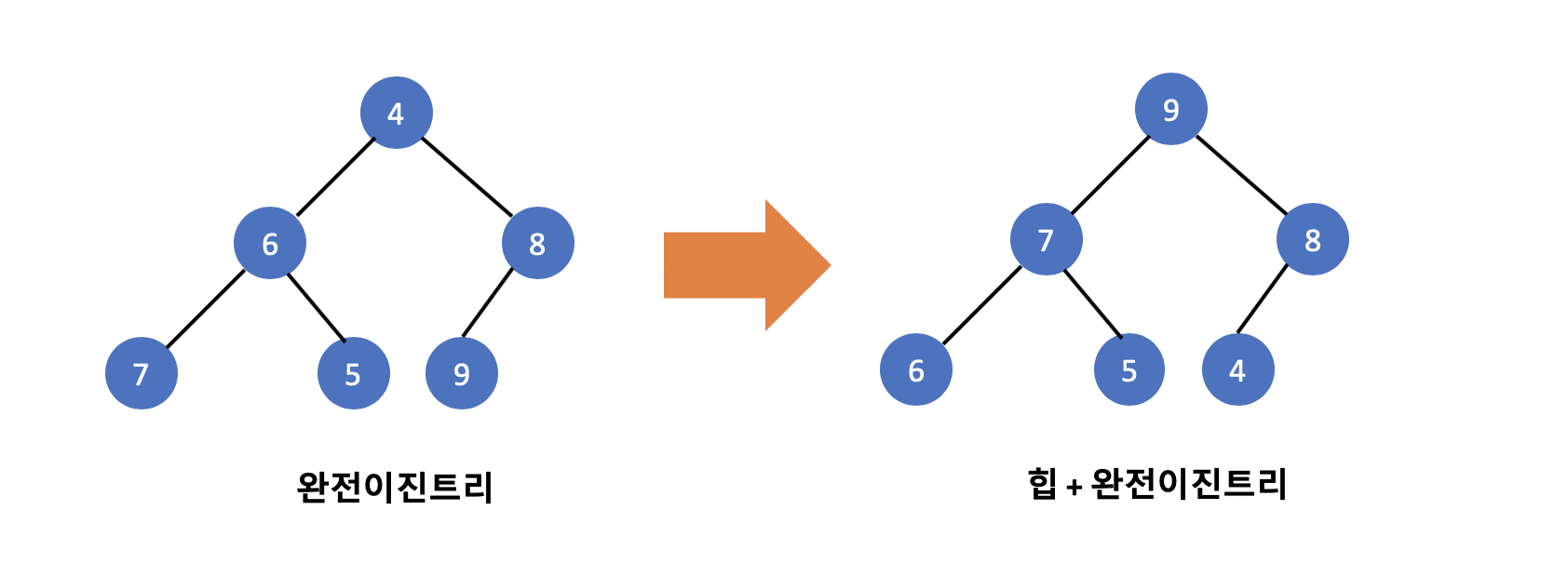
위의 사진 중 왼쪽은 힙이 아닌 완전이진트리입니다. 부모의 값이 자식의 값보다 크거나 또는 작지가 않으며 힙의 조건에 성립하지 않으며 무작위입니다. 그러나 반면에 오른쪽 트리는 왼쪽의 완전이진트리에서 힙의 조건에 각 값들을 수정한 것을 볼 수 있습니다.
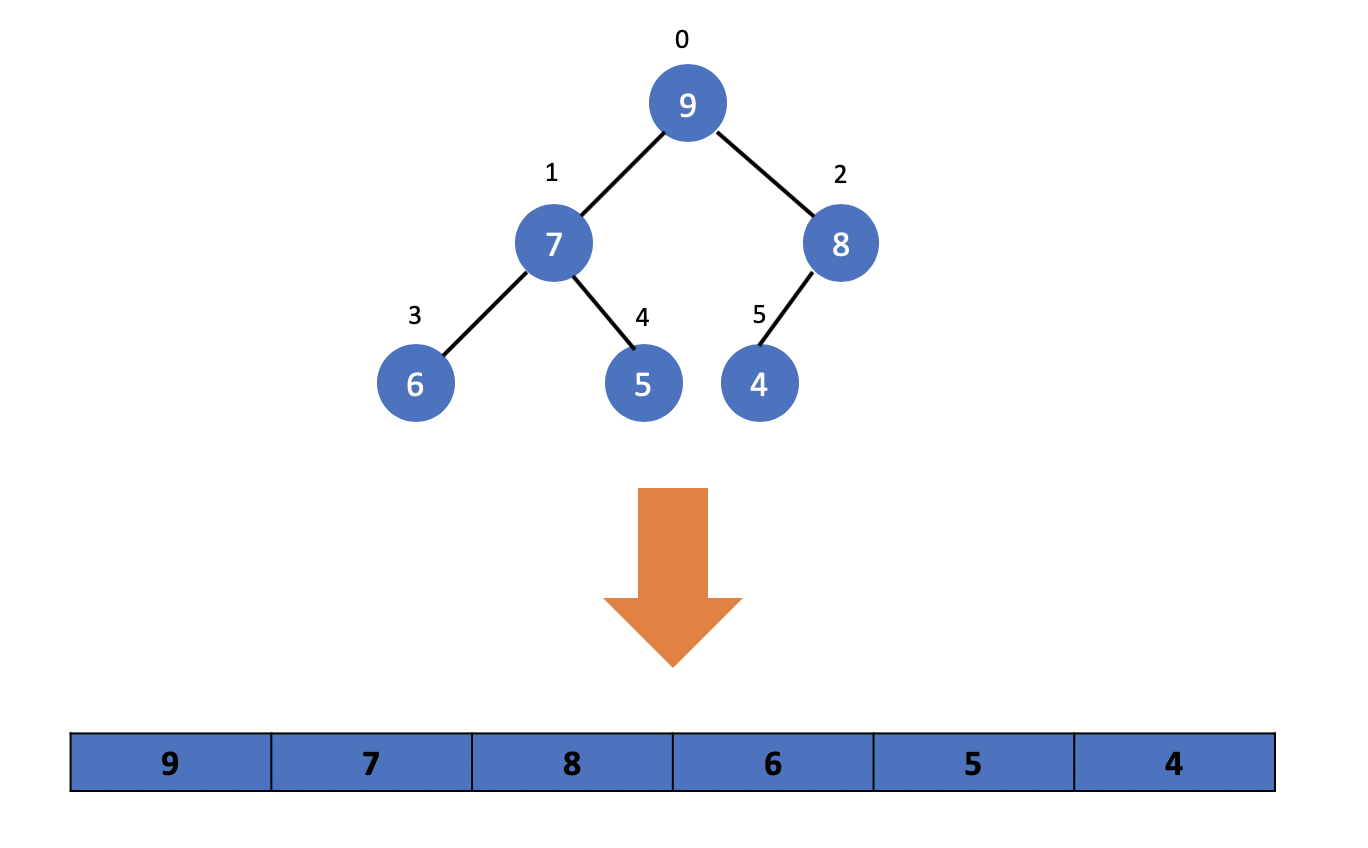
위의 사진과 같이 힙 완전이진트리의 요소들을 배열에 저장하는 과정은 먼저 가장 위쪽에 있는 루트를 0번째 인덱스에 넣으며 그리고 한 단계 아래로 내려가 왼쪽에서 오른쪽으로 각 값들을 저장합니다. 이 과정을 계속 반복하며 배열에 순차적으로 값을 저장합니다.
위의 과정을 거쳐 힙의 요소를 배열에 저장하였다면 부모와 자식의 인덱스 사이에 아래와 같은 관계가 성립이됩니다. 공식에서 i는 배열에서의 각 요소의 인덱스를 의미하며 이 공식들을 사용하여 트리를 직접 구현하지 않고도 배열로만 힙의 구조를 알 수 있습니다.
힙 요소 배열에서 부모와 자식의 관계 공식
1. 부모는 x[(i - 1) / 2]
2. 왼쪽 자식은 x[(i * 2) + 1]
3. 오른쪽 자식은 x[(i * 2) + 2]
그럼 이번에는 힘 정렬을 실제로 구현해보기 전 힙 완전이진트리의 루트를 없애고 힙 상태를 유지하는 방식에 대해서 공부하겠습니다. 힙 정렬은 가장 큰 값이 루트에 위치하는 특징을 이용하는 정렬 알고리즘이다보니 이 내용이 정말 중요하다고 말할 수 있습니다.
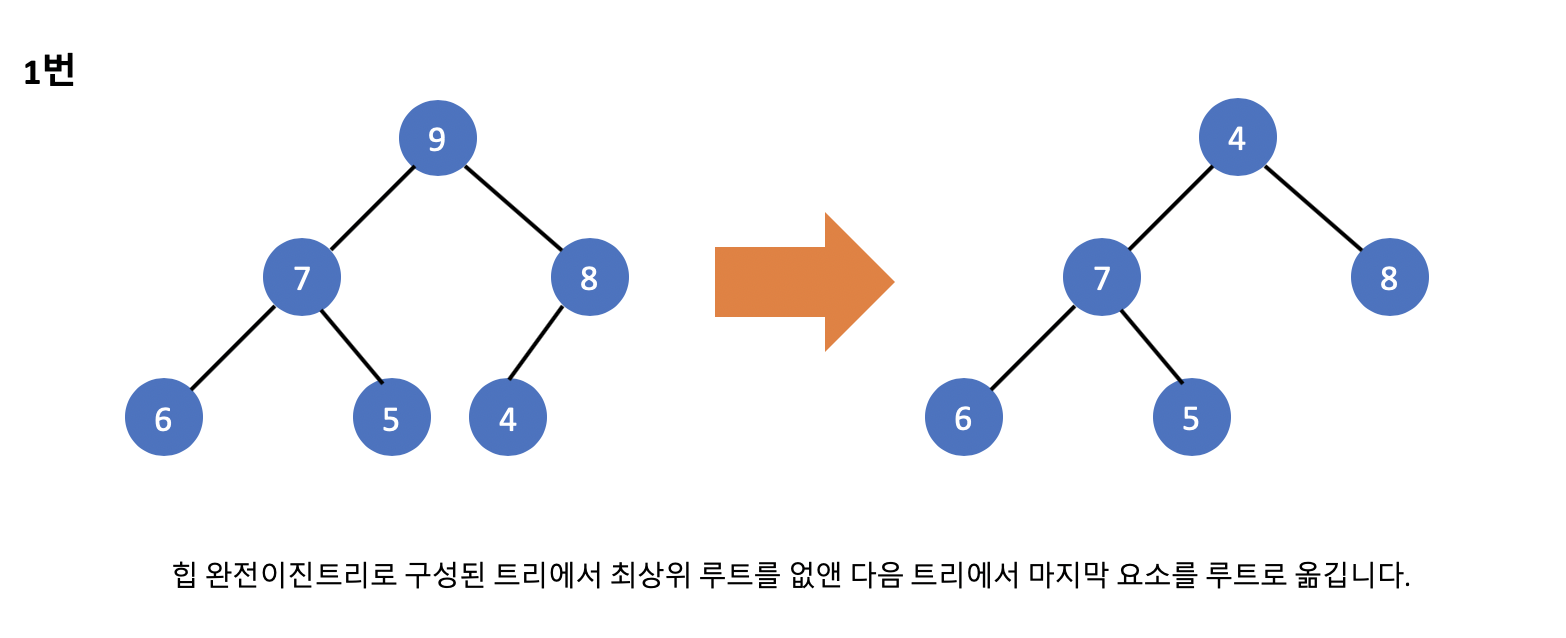
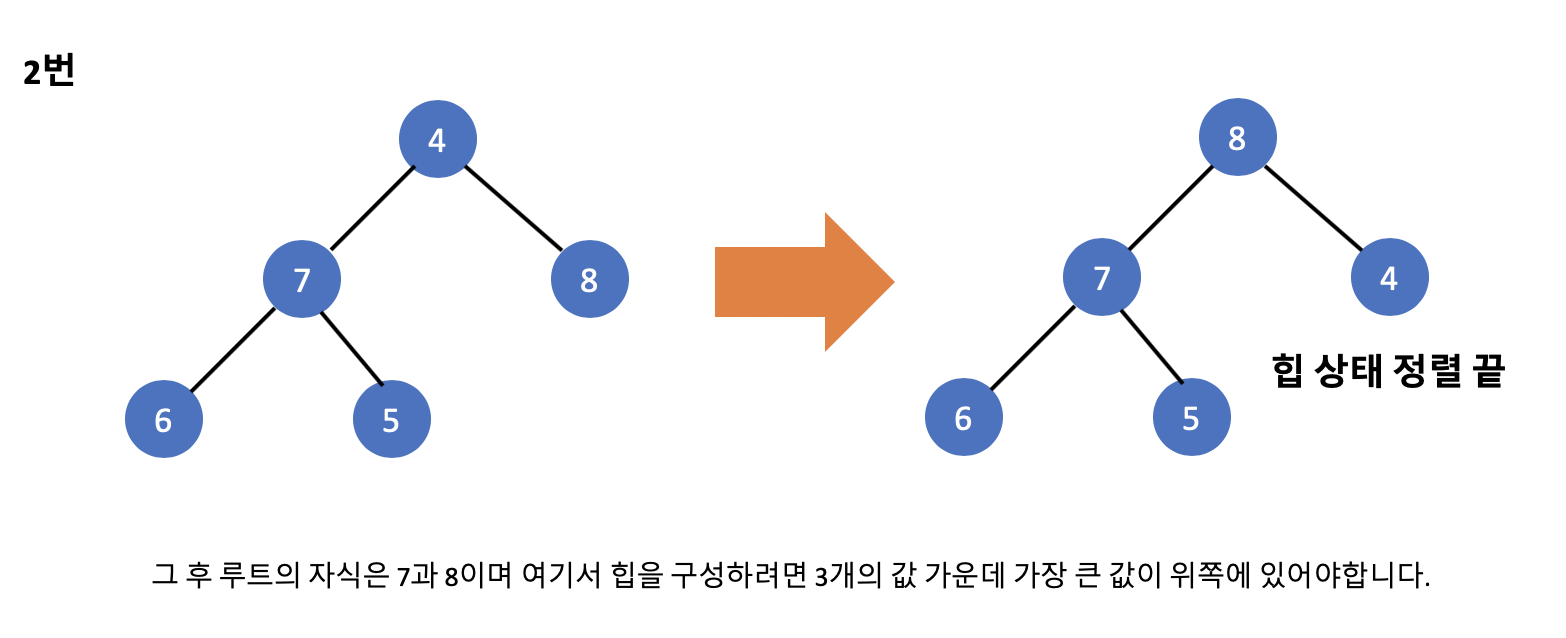
위 사진의 설명처럼 기존의 루트를 제거하고 힙 상태를 유지하는 예시입니다. 간단히 다시 설명하자면 기존의 최상위 루트를 없앤 다음 트리에서 가장 아래의 마지막 요소를 루트로 설정하며 루트 이외의 값들은 현재 힙 정렬이 되어있기 때문에 루트만 제자리로 배치를 하면 됩니다. 그 후 루트의 자식들과 값을 비교해 그 값들 중에서 가장 큰 값을 위쪽으로 올려가면서 힙 정렬을 진행하면됩니다.
기존의 루트를 없앤 후 힙 상태 유지하는 순서
1. 기존의 루트를 꺼냅니다.
2. 마지막 요소를 루트로 이동합니다.
3. 자기보다 큰 값을 가진 자식 요소와 자리를 바꾸며 아래쪽으로 내려가는 작업을 반복합니다.
그럼 이제 위의 방식을 활용하여 힙 정렬 알고리즘을 구현해보기 전 흐름에 대해서 먼저 알아보겠습니다. 아래의 구조는 실제로 힙 정렬을 구현하는 모습이며 위에서 배웠던 방식을 그대로 이용하며 트리의 루트 값들을 배열 뒤로 순차적으로 보냅니다.
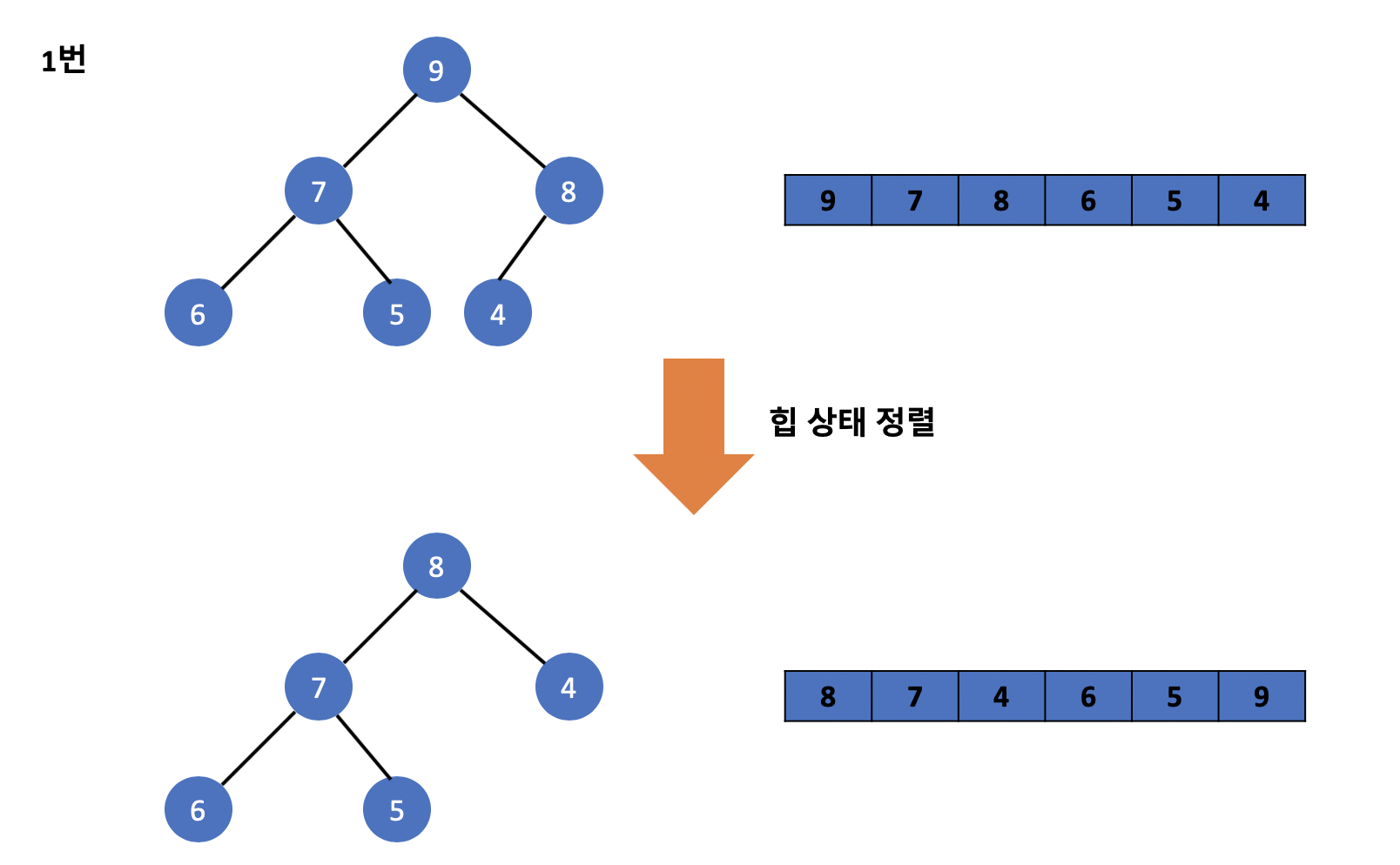
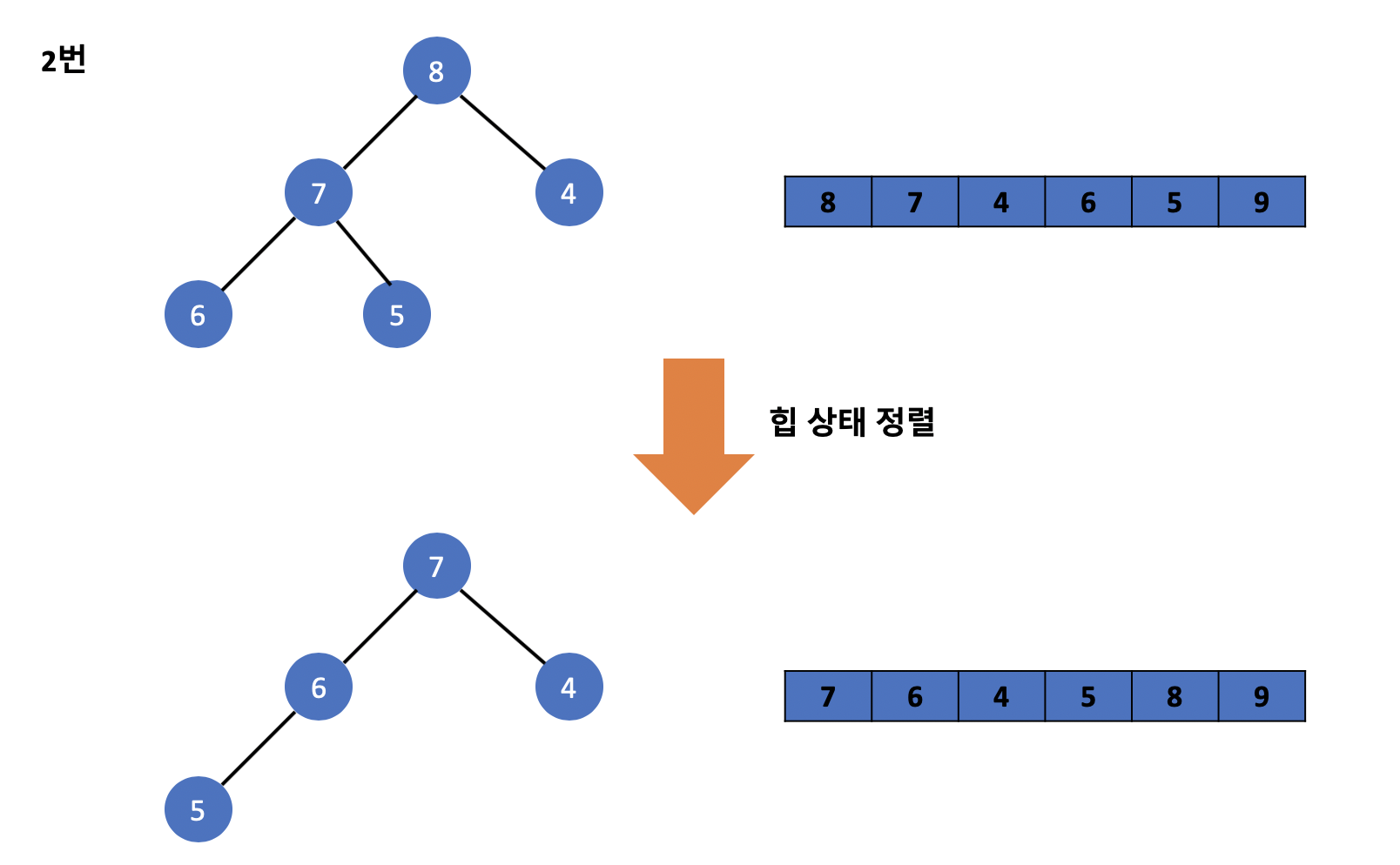
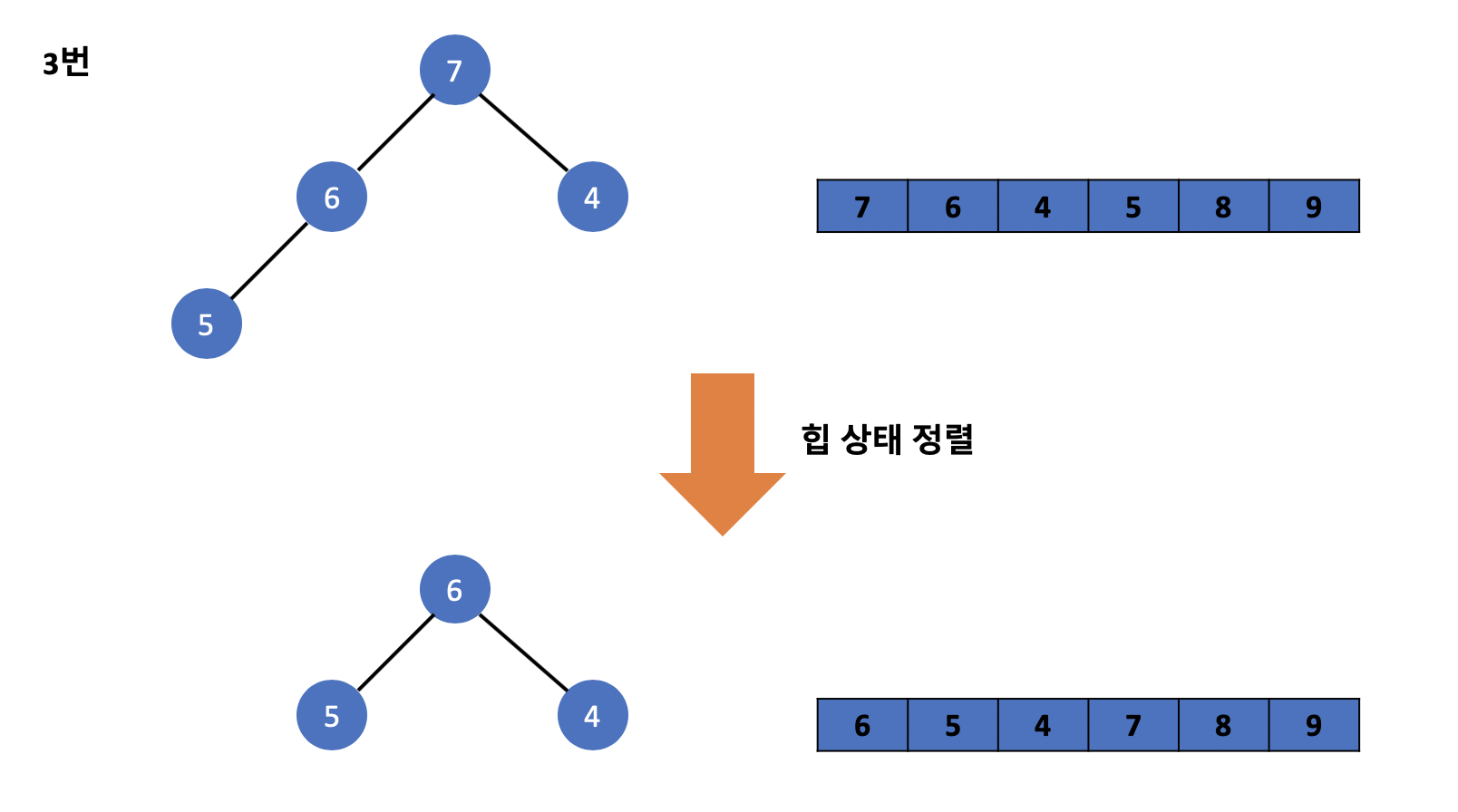
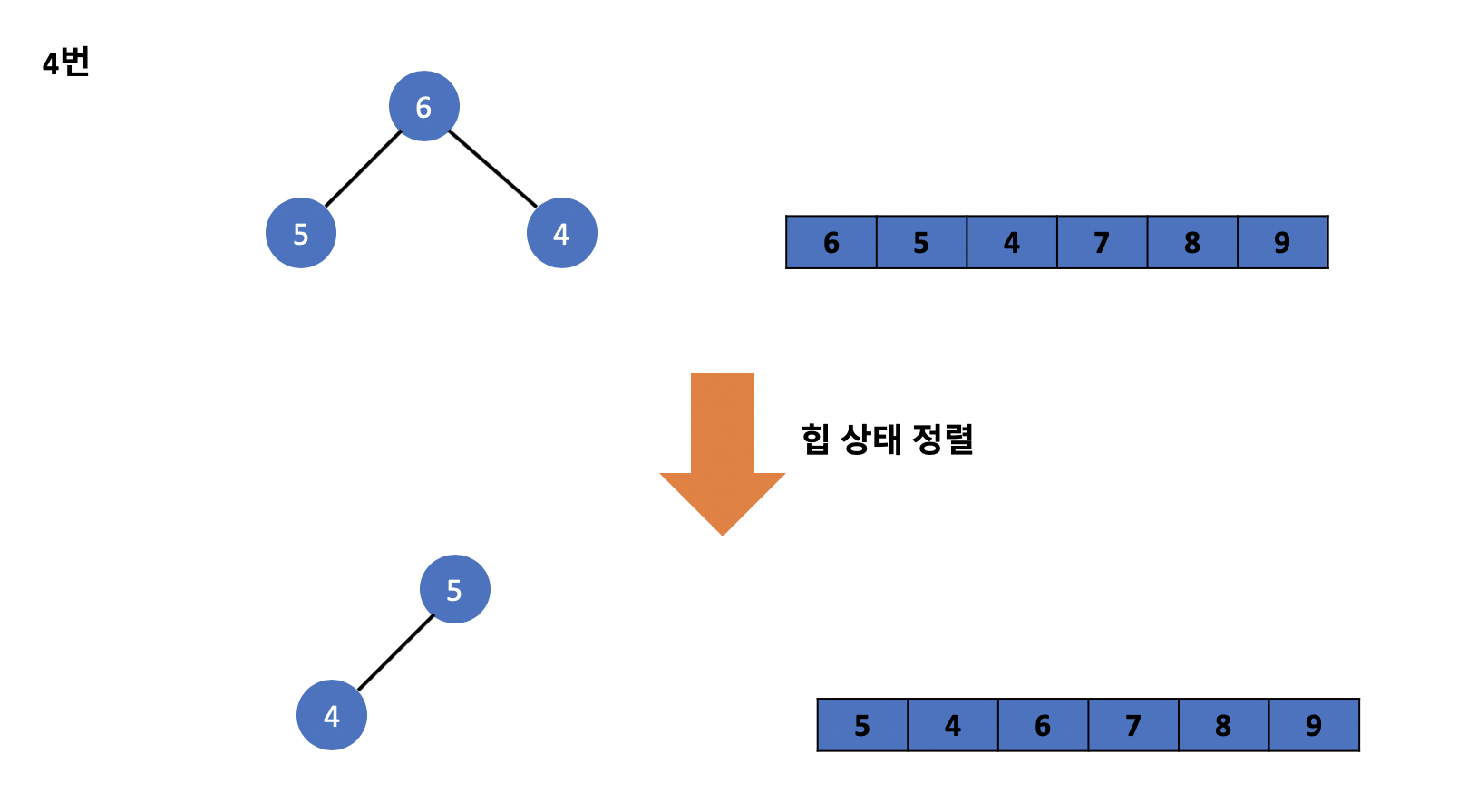
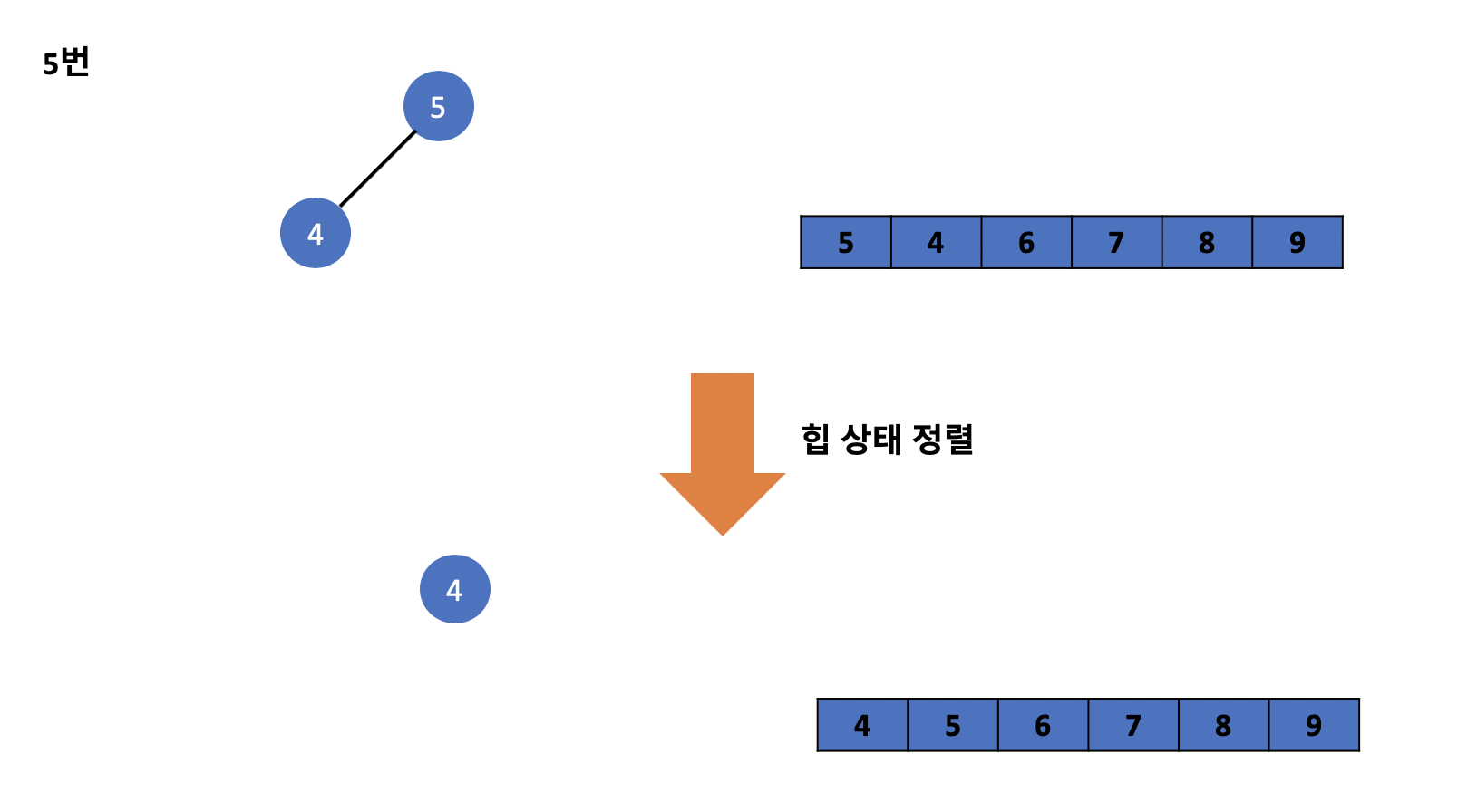
위와 같은 과정을 거친다면 배열에는 앞에서부터 순차적으로 오름차순으로 트리에 존재하던 값들이 정렬된 모습을 볼 수 있습니다. 이 과정을 힙 정렬이라고 부르며 앞에서 배웠던 힙 상태 유지하기 기술을 활용하여 힙 정렬을 구현한 것을 볼 수 있습니다.
힙 정렬 알고리즘의 순서도에 대해서
1. 변수 i의 값을 n - 1로 초기화합니다.
2. x[0]과 x[i]를 바꿉니다.
3. x[0] ~ x[i - 1]을 힙 상태로 정렬합니다.
4. i의 값을 1씩 줄여 0이 되면 끝이 납니다.
힙 정렬 알고리즘의 순서도에 대해서 간략히 설명하였습니다. 1번에서 3번의 순서로 진행이되며 만약 i의 값이 0이 아니라면 다시 2번의 과정으로 돌아가 i의 값이 0이 될 때가지 똑같은 방식으로 힙 정렬 알고리즘을 반복하여 수행하면 됩니다. 크게 어렵지 않습니다.
public class HeapSort {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("힙 정렬");
System.out.print("요솟수 : "); int input = scanner.nextInt();
int x[] = new int[input];
for(int i = 0; i < input; i++){
System.out.print("x[" + i + "] : ");
x[i] = scanner.nextInt();
}
heapSort(x, input);
System.out.println("오름차순으로 정렬했습니다.");
for(int i = 0; i < input; i++){
System.out.println("x[" + i + "] = " + x[i]);
}
}
public static void heapSort(int x[], int input){
for(int i = (input - 1) / 2; i >= 0; i--){
downHeap(x, i, input - 1);
}
for(int i = input - 1; i > 0; i--){
swap(x, 0, i);
downHeap(x, 0, i - 1);
}
}
public static void downHeap(int x[], int left, int right){
int temp = x[left];
int child;
int parent;
for(parent = left; parent < (right + 1) / 2; parent = child){
int cl = parent * 2 + 1;
int cr = cl + 1;
child = (cr <= right && x[cr] > x[cl]) ? cr : cl;
if(temp >= x[child]) break;
else x[parent] = x[child];
}
x[parent] = temp;
}
public static void swap(int x[], int idx1, int idx2){
int temp = x[idx1];
x[idx1] = x[idx2];
x[idx2] = temp;
}
}위의 코드는 앞에서 저희가 공부한 힙과 힙 정렬의 개념을 활용하여 코드로 구현한 것입니다. 코드의 내용은 위에서 설명한 내용을 자세히 이해를 하였다면 어렵지 않게 이해를 할 수 있을 것이라고 생각합니다. 간략히 코드에 대해 설명을 하면 heap 메서드는 배열 x를 힙 정렬하는 메서드이며 아래의 downHeap 메서드는 배열 x 가운데 x[left] ~ x[right]의 요소를 힙 상태로 만드는 메서드입니다.
👍 글을 마치며
이렇게 정렬 알고리즘에 대한 설명을 모두 마쳤습니다. 정렬에 관한 내용은 이전에 배운 내용들보다 훨씬 양이 많으며 제가 위에 작성한 내용보다 더 다양한 종류의 정렬 알고리즘 또한 존재합니다. 위의 내용을 한 번에 이해하려고하는 것보다 자기에게 필요한 내용을 선택하여 공부하는 것이 더 효율적이라고 저는 생각합니다. 이 글을 적어내기 위해 약 일주일이라는 시간이 소모되었으며 책과 다양한 사람들의 문서들을 참고하여 글을 작성하였습니다. 혹시나 글에 틀린점이나 개선점이 있다면 댓글을 남겨주시면 감사하겠습니다.
참고 : Do it 자료구조와 함께 배우는 알고리즘 입문 자바 편
'프로그래밍 기초 > Data structure & Algorithm' 카테고리의 다른 글
| 완주하지 못한 선수 (2) | 2020.07.21 |
|---|---|
| 크레인 인형뽑기 게임 (2) | 2020.07.15 |
| 재귀에 대해서 (0) | 2020.03.05 |
| 큐에 대해서 (2) | 2020.02.13 |
| 스택에 대해서 (0) | 2020.02.12 |



